Hoy quiero hablarles del "Flex Profiler", una herramienta incluida en el Flex Builder que nos permite realizar sesiones de profiling (para optimizar el rendimiento y el uso de recursos).
Para utilizarlo tan sólo debemos crearnos un perfil de "profile", esto se realiza de la misma forma que un perfil para ejecutar o para depurar la aplicación. Tan solo debemos picar en el botón

teniendo seleccionado el proyecto o bien picando en el mismo botón en la opcion
otros. Al hacer esto nos mostrara la pantalla de configuracion del perfil.
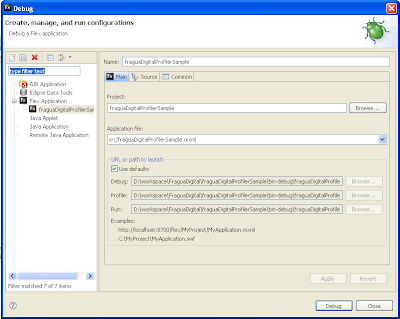
Como vemos en la pantalla podemos seleccionar el proyecto, el fichero principal del proyecto (el que contiene el tag Application) y las URLs que se usarán para lanzar la aplicación. Ahora ya podemos lanzar la sesión de profiling desde el boton profile. Al lanzarlo se nos abrirá la perspectiva "Flex Profiling" mostrandonos la pantalla de conexión.
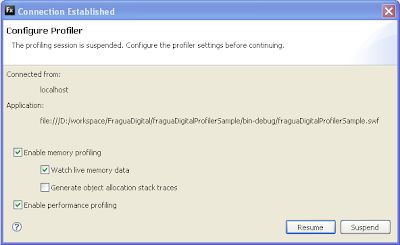
Desde dicha pantalla podemos seleccionar si queremos ejecutar el profiling de memoria, de rendimiento o de ambos. Asimismo, para el profiling de memoria podemos indicar:
- Si queremos ver los objetos vivos en memoria ("watch live memory data"), que nos muestra el panel "Live Objects" con información de que clases se han instanciado, cuantas instancias existen, la memoria que consume etc.
- Si queremos generar la traza de asignación de los objetos ("Generate object allocation stacktraces"), que capturará la traza cada vez que se genere un objeto. Tenemos que tener mucho cuidado con esta opcion ya que puede ralentizar el profiler y usar mucha mas memoria.
Es mejor fijarnos ciertos objetivos en cada sesion y no tratar de mejorar el rendimiento y el uso de memoria en la misma sesión.
Garbage CollectorAntes de meternos en harina con el profiling de la memoria, tenemos que entender como funciona el
garbage collector de la máquina Flash Player. El garbage collector se basa fundamentalmente en dos técnicas el "
Reference Counting" y el "
Mark and Sweep".
El "reference counting" basicamente consiste en que cada objeto mantiene un contador de referencias, cada vez que un objeto hace referencia a otro se incrementa el contador de referencia del objeto apuntado. Cuando el contador de referencias es cero el objeto puede ser eliminado. El reference counting presenta un problema serio, y es que si se forma una referencia circular (por ejemplo: A apunta a B y B apunta a A) el objeto nunca será liberado. En el caso concreto de Flex, debemos tener mucho cuidado con esto ya que es muy probable que
creamos que un objeto no esta siendo referenciado por nadie y aun así tenga referencias, en este caso debemos echarle un ojo a los listener que pueda tener asociados el objeto, una buena precaución es definir siempre los listeners como
weak references, que crean la referencia pero no incrementan el contador de referencias.
El "Mark and Sweep" es una técnica de recolección en la que cuando el garbage collector realiza una pasada (recorriendo el arbol de referencias de los objetos) , comprueba si el objeto puede ser liberado (contador de referencias a cero) si es así lo marca y a su vez, en la misma pasada, si el objeto esta marcado lo elimina.
Otra cosa a tener en cuenta es la frecuencia con la que se ejecuta el garbage collector, cosa que es impredecible, ya que en mi opinión se ejecuta cuando le parece. En teoría, hay un sofisticado algoritmo, que comprueba cuando debe ejecutarse el garbage collector, que se ejecuta cuando se asigna memoria, pero no he encontrado a nadie que lo haya sabido explicar XD.
Profiling de MemoriaEmpezaremos con una sesión para mejorar el uso de la memoria. Es muy importante realizar estas sesiones ya que en ellas podremos detectar posibles
"memory leaks" (fugas de memoria, es decir memoria que se asigna pero que nunca se recupera). Por lo general para esta sesión, suelo activar la opcion "watch live memory data". Veremos esta pantalla:

Arriba a la izquierda se muestra la pestaña con los datos del profile y los datos guardados. Tenemos varios botones que nos permiten forzar la ejecución del garbage collector, tomar una instantanea de la memoria, etc. (ya iremos hablando de los botones según los usemos).
Arriba a la derecha se muestra una gráfica con el consumo de memoria, donde se ve el consumo de memoria actual y los picos de memoria.
Abajo tenemos la pantalla de "Live Objeccts", con información de que clases se han instanciado, cuantas instancias existen, la memoria que consume. Tenemos que tener que también muestra datos acumulativos (
"cumulative instances" y
"cumulative memory") y que eston son la suma total de todo durante la ejecución de la aplicación.
Para realizar el profiling debemos tomar una o varias "memory snapshots" en momentos determinados en los que la aplicación haya ejecutado cierta funcionalidad que queremos comprobar. Comparando dichas instantaneas de la memoria podemos identificar instancias de objetos que no se hayan eliminado cuando deberían haberse eliminado. Las snapshots cuando se toman van apareciendo en la pestaña "Profile" (arriba a la izquierda). con un doble click en la snapshot nos muestra la pestaña "Memory Snapshot" , en la que veremos la informacion de los objetos y sus referencias, con doble click ira a la pestaña "Object References", donde vemos las referencias del objeto. De esta forma podemos ir navegando por los objetos para identificar con quien se relaciona y ver porque no ha sido eliminado por el garbage collector.
Profiling de rendimientoEn segundo lugar podemos ejecutar una sesión de profiling para comprobar el rendimiento. en este caso Flex Profiler nos mostrará una pantalla en la que podemos ver el número de funciones y/o procedimientos que se han ejecutado, el número de llamadas, el tiempo que ha tardado y su media.
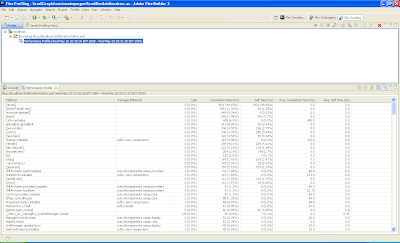
Con esta información podemos detectar secciones del código que puedan suponer un cuello de botella y que estén ralentizando la aplicación. Por tanto podremos optimizar dichas secciones para mejorar su rendimiento, en este caso la mejora la mediremos por el tiempo que tarde el método. Sobra decir, que es importante fijarse tanto en los procesos que tardan mucho en ejecutarse como en aquellos proceso que se ejecutan muchas veces.
Bueno, creo que ya es bastante información para asimilarla de una sola vez así, que lo voy dejando por hoy para que vayais digiriendolo.
P.D: podemos encontrar mucha información sobre esto en el sitio web de adobe (
aqui).
Saludos.



















